 A Space for Thoughtful
A Space for Thoughtful 


Is AI for Data Analytics the Competitive Edge Businesses Need?
Summarize with:
We can often get caught up in the hype surrounding artificial intelligence (AI) and its potential consequences for our data. It’s fascinating to consider some interesting insights from large datasets. But many business leaders still have the same practical questions: How does AI really add value to data analytics? What does a good return on that investment (ROI) look like?
Those strange things become clearer when you dig deeper. For example, questions about data quality aren’t things that people in academia talk about. AI models will fail if they don’t have accurate, clean data. This, in turn, means you cannot rely on the results completely.
Then there’s the human side of things: What new skills and ways of thinking do our teams need to really do well with AI? In the often-tricky world of data privacy and security, how do we deal with biases that could affect our important business decisions? And once an AI project is initiated, how do you even start to inculcate it across the whole company? These questions will decide who gets ahead and what new AI trends will change everything.
Table of Contents:
- What are the Biggest Data Quality Challenges for AI Analysis?
- How Does AI Improve Data Analysis Accuracy and Efficiency Today?
- How Can You Reduce AI Bias in Critical Business Analytics?
- What Data Privacy and Security Risks Does AI for Data Analytics Pose?
- How to Scale AI Analytics Solutions Across Enterprise Operations Effectively?
- How Do Senior Leaders Measure AI Analytics Project Success?
- What Is the Tangible ROI of AI Investment for Enterprise Data Analysis?
- How Do We Integrate AI Tools With Our Existing Data Infrastructure?
- What Ethical Considerations Arise With AI-Driven Data Analysis Decisions?
- A Final Word
What are the Biggest Data Quality Challenges for AI Analysis?
“Garbage in, garbage out” is one of the oldest rules in computing, but AI takes this idea to an uncomfortable level. We need to stress how important it is to have accurate data. One of the prospective clients we were talking with had their shiny new AI system making predictions based on data, where one-fourth of customer records were based on outdated information. The outcome? Let’s just say the board meeting was definitely not a happy place.
The first challenge hits organizations right in the spreadsheets: inconsistent data formats. When marketing uses “Q4-2024” but finance writes “2024Q4” and operations prefers “Oct-Dec 2024,” AI systems throw their digital hands up in confusion. One telecommunications company found eleven ways employees recorded customer status across systems. Eleven!
Missing data creates another headache entirely. Training AI models on incomplete datasets can lead to blind spots that can derail analysis. Then there’s the dirty secret nobody talks about at conferences: duplicate records. When John Smith, J. Smith, and Smith, John all represent the same customer but live in different systems, AI treats them as three people. One of our client discovered they were triple-counting their best customers’ purchases, inflating their loyalty program effectiveness.
Historical data presents its own special nightmare. Company mergers, system migrations, and changing business processes create data archaeologies that would make Indiana Jones nervous. One organization tried analyzing ten-year trends, only to discover that their pre-2019 data used completely different categorization standards. The AI dutifully analyzed apples against oranges, producing insights that looked impressive but meant nothing.
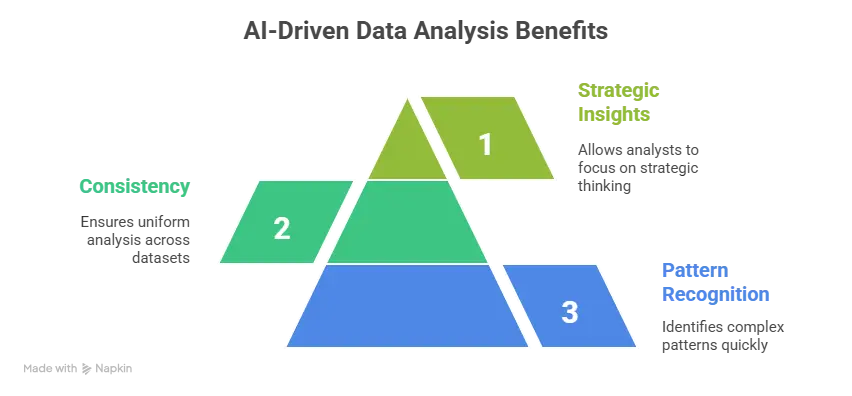
How Does AI Improve Data Analysis Accuracy and Efficiency Today?
Picture a retail manager scrolling through thick monthly sales charts that took her team almost a month to fill out. By the time the insights reach her desk, market conditions have already shifted. Sound familiar?
AI changes this game entirely, but not in the way most vendors promise. The real improvements come in three flavors that matter to executives.
1. Blazing-Fast Pattern Recognition
Humans are incapable of matching the speed at which pattern recognition happens. An AI system can find anomalies in transaction data in milliseconds, which would take an analyst days to do in Excel.
2. Consistency That Never Sleeps
Second, there’s the accuracy paradox. AI doesn’t get tired at 6 PM on Friday. It doesn’t accidentally transpose numbers or skip rows 1,247 through 1,251 because the coffee ran out. When a pharmaceutical company switched to AI-assisted clinical trial analysis, error rates dropped significantly. In other words, that’s what consistency at scale is all about.
3. Freeing Analysts for Strategic Insights
But here’s where executives need to pay attention: efficiency gains go beyond speed. They free analysts to ask better questions. Give it some thought. Your team will have more time to work on insights that really matter if they don’t have to spend as much time cleaning up data. That’s where the real value is. Teams can now spend less time cleaning data and making reports and more time interpreting it strategically.
How Can You Reduce AI Bias in Critical Business Analytics?
Fixing AI bias is never that easy, particularly when it comes to crucial business analytics like supply chain disruption prediction or credit scoring. Frankly, it starts with an almost philosophical question: What kind of fairness are we even aiming for? Because that’s not always straightforward.
Take the data. Everyone says, “Clean your data.” But bias isn’t a smudge you can just wipe off. It’s often baked in, historically. Imagine using decades of past performance reviews to train an AI for employee promotions. If those reviews subtly favored one demographic over another, even unconsciously, your AI will learn that preference. Our data collection lens should be critically scrutinized before we touch an algorithm. Sometimes, you might even have to, well, de-emphasize certain data points or actively seek out counterexamples to ensure fairness. It’s not perfect, it’s messy.
Then there’s the model itself. It’s not enough to just build a highly accurate predictive model. We have to ask: accurate for whom? Does it perform equally well across different customer segments? Credit risk models might be ‘accurate’ overall, but if they consistently flag more false positives for, say, a particular ethnic group, that’s more than a statistical anomaly; it’s a real issue. This entails switching to explicit fairness metrics from conventional accuracy metrics. Are we guaranteeing equal rates of error? Or equal chances? These are moral positions rather than merely technical decisions. To be honest, it can occasionally feel like diplomacy to get a team to agree on the appropriate fairness metric.
What Data Privacy and Security Risks Does AI for Data Analytics Pose?
When we talk about AI analytics, most people imagine intelligent algorithms making things faster and more efficient. Indeed, they do. However, beneath that glossy exterior is a maze of security and privacy issues with data that keep many of us up at night.
Think about it: AI models are insatiable data devourers. They thrive on massive datasets. An algorithm isn’t just storing your online purchases, your location data from an app, or even the activity logs from your smart home device when you feed it mountains of information. It’s building connections, inferring patterns we might not even recognize. It can piece together a remarkably intimate profile of an individual, even if each individual data point seemed anonymized or harmless on its own.
Then there’s the quiet but dangerous problem of bias. Sadly, our world is packed with unfair opinions, and the facts we gather often carry those stains. When an AI learns from old records that turned away loan applicants from certain groups, it picks up that same unfair pattern and repeats it. The system simply follows the example provided, without malicious intent. The result, however, is familiar: discrimination hides behind the cool mask of an unbiased formula. We’ve watched this unfold in hiring software, court risk scores, and even patrolling practice.
Beyond that, the systems themselves are targets. A growing concern is adversarial attacks, where clever, subtle changes to data inputs can mislead AI. Imagine someone tweaking a few pixels on a stop sign just enough for an autonomous vehicle’s AI to miss it. Or injecting noise into customer data to manipulate credit scores. It’s a cat-and-mouse game, where the stakes are incredibly high. And frankly, the ‘black box’ problem, where we don’t fully understand why an AI made a particular decision, just compounds all these issues. How do you audit for privacy violations if you can’t trace the decision-making process? It feels a bit like trusting a magical oracle, doesn’t it? It is still a challenge to make these powerful tools truly transparent and accountable
How to Scale AI Analytics Solutions Across Enterprise Operations Effectively?
Scaling AI analytics… you’ve probably run across that line at least once this week. Most people picture massive servers or fancy algorithms, but the real work happens in day-to-day connections inside the business. To make an intelligent program genuinely useful to every team, we first have to spot all the moments where people interact with the data.
The data itself is one of the first things that trips everyone up, almost every time. You make a great model in a clean, well-organized sandbox and try to use it in the real world. Out of nowhere, you’re in a messy sea of inconsistent identifiers, missing values, and data sources that haven’t talked to each other since the last millennium.
Then there’s the model itself. Developing one is one thing; keeping it humming, accurate, and relevant in a dynamic business environment. That’s a whole other ballgame. Think of it: a model trained on last year’s customer behavior might totally miss the mark today because markets shift, preferences change. You need a disciplined way to monitor its performance, to retrain it with fresh data, perhaps even to retire it gracefully when it’s truly past its prime. This becomes a lifelong journey, an ongoing commitment that loops through observation, adaptation, and refinement. Honestly, it often feels more like parenting than engineering sometimes. You’re constantly nurturing, correcting, and setting boundaries.
How Do Senior Leaders Measure AI Analytics Project Success?
How do you know AI is worth it? It’s not just gut feel. CXOs need numbers. Start with goals: Is your organization chasing revenue, efficiency, or learner satisfaction? Tie AI to that. If it’s satisfaction, track course ratings pre- and post-AI. Hard data beats hunches.
Model accuracy’s a clue too. If AI predicts dropouts with 95% precision, that’s gold. Time matters. How fast does it pay off? A quick win, like cutting report time from days to hours, builds faith. Cost savings? Tally it, fewer staff hours, less waste.
But here’s the rub: adoption. If your team won’t touch it, it’s a bust. Ask them with surveys or chats. A retailer once bragged about AI boosting sales, but the real metric was staff using it daily. Mix these things together: goals, accuracy, speed, savings, and buy-in. You’ve got a yardstick. If you miss one, you’ll have to guess.
What Is the Tangible ROI of AI Investment for Enterprise Data Analysis?
CFOs love this question because it cuts through the hype. Let’s talk real numbers, not vendor promises. Yes, return on investment (ROI) calculations for AI get tricky. Reduced analysis time, fewer errors, and faster insights are only part of the story. The transformative value often hides in second-order effects.
Consider the insurance firm that implemented AI for claims analysis. Direct benefit: 60% faster claim processing. Valuable, sure. But the real ROI came from what happened next. Faster processing meant happier customers. Happier customers renewed policies at 15% higher rates. The lifetime value calculation suddenly made that AI investment look like pocket change.
Smart organizations track both hard and soft ROI metrics. Hard metrics include analysis cost per insight, time-to-decision improvements, and error reduction rates. Soft metrics cover employee satisfaction (analysts doing strategic work instead of data janitor duties), competitive advantages from faster market responses, and risk mitigation from better predictive capabilities.
The harsh truth? Not every investment in AI yields a successful outcome. Companies that believe AI is a magic fix and fail to adapt their processes typically lose money. However, companies that carefully integrate AI into their analysis workflows usually see a return on their investment within 12 to 18 months. Additionally, the returns improve as teams become more proficient in utilizing AI. The most effective way to achieve a solid return on investment is to start with something small, prove it succeeds, and then expand on the successful aspects.
How Do We Integrate AI Tools With Our Existing Data Infrastructure?
“We want to use AI, but our data is stuck across nine systems built over the past two decades.”
Sound familiar? Welcome to every enterprise’s integration nightmare. The good news is that you don’t have to start over from scratch.
Smart integration begins with a candid assessment of the current infrastructure. But the temptation to modernize everything simultaneously kills more AI initiatives than any technical challenge. A retail chain learned this after spending a few million dollars on a “complete digital transformation.” Two years later, they’d migrated a quarter of their data and generated zero business value. Meanwhile, their competitor used simple connectors to feed existing data into cloud-based AI tools. Guess who captured market share?
Technical architecture matters, but not how most executives think. The question isn’t “Should we move to the cloud?” or “Do we need a data lake?” It’s “What’s the minimum viable integration that delivers value?” Modern AI tools increasingly handle messy, distributed data.
Here’s what actually works: Start with read-only connections to existing systems. Let AI tools pull data without risking production operations. Use middleware to standardize formats on the fly rather than restructuring databases. Build feedback loops gradually. Let AI insights flow back through existing reporting channels before attempting real-time integration.
What Ethical Considerations Arise With AI-Driven Data Analysis Decisions?
The algorithm recommended denying mortgage applications from specific neighborhoods. Technically correct based on historical data? Yes. Ethically defensible? Absolutely not.
This scenario played out at a major bank, highlighting the minefield executives navigate when AI influences significant decisions. The ethical challenges go far beyond avoiding obvious discrimination.
Consider the healthcare network whose AI identified patients likely to miss appointments. Brilliant for scheduling efficiency. Then someone asked: “What happens to patients the AI flags as unreliable?” Turns out, the system inadvertently created a priority tier system, offering premium appointment slots to “reliable” patients while pushing others to less convenient times. The reliable patients? Generally wealthier with flexible work schedules. The ethics committee had questions.
Transparency creates another thorny issue. When AI denies a loan, flags a resume, or predicts employee turnover, people deserve explanations. But complex neural networks don’t readily explain their reasoning. “The algorithm said so” doesn’t cut it in the boardroom or courtroom.
Another challenge is data consent. Organizations collect information for specific purposes, then AI finds novel uses for that same data. Does the retailer use purchase history for inventory planning? Fine. Using that same data to infer health conditions for insurance partners? That’s a lawsuit waiting to happen.
The competitive pressure makes ethics harder. If competitors use AI to maximize profit regardless of fairness, ethical organizations face real disadvantages. Leading organizations establish AI ethics boards before problems arise. These committees wield real power to veto implementations that cross ethical lines. They go beyond feel-good gatherings to make actual decisions with teeth. They ask tough questions: Who benefits from this analysis? Who might be harmed? How do we explain decisions to affected parties? What would happen if this made headlines?
The most successful approach treats ethics as a feature, not a bug. Organizations building fairness into their AI processes often discover unexpected benefits.
A Final Word
The journey toward meaningful AI for data analysis becomes an evolution rather than a destination. Organizations that succeed won’t be those with the biggest budgets or fanciest algorithms. Victory belongs to those who ask better questions, embrace uncomfortable truths, and build systems that amplify human judgment rather than replace it. The challenges are real.
Data remains messy. Biases lurk in algorithms. Security threats multiply. Cultural resistance persists. But so do the opportunities. Every insight gained, every decision improved, and every pattern discovered creates compound advantages that accelerate over time.
Unlock the power of AI data insights with Hurix Digital’s expert services. Let’s build human-centered systems that drive real impact.
Contact us today and start your transformative journey.
Summarize with:

Vice President – Content Transformation at HurixDigital, based in Chennai. With nearly 20 years in digital content, he leads large-scale transformation and accessibility initiatives. A frequent presenter (e.g., London Book Fair 2025), Gokulnath drives AI-powered publishing solutions and inclusive content strategies for global clients