 Upcoming Masterclass | Build an Army of Brand Evangelists using Training & Development | November 20th, 8:30 AM PDT | 11:30 AM EDT | 10:00 PM IST
Upcoming Masterclass | Build an Army of Brand Evangelists using Training & Development | November 20th, 8:30 AM PDT | 11:30 AM EDT | 10:00 PM IST


Are You Ready for AI-Driven Learning & Development?
Plenty of senior leaders now feel a quiet tension around what to do with AI in L&D. They sense there is promise hiding beneath the noise, yet they also carry scars from past tech waves that soaked up budget and produced thin outcomes. Boards ask for speed. Teams ask for clarity. Vendors keep waving dashboards. Somewhere in the middle sits a basic question: What does “ready for AI in L&D” even look like in practice?
The recent Hurix Digital L&D Maturity Index report surfaced a telling split: executives rate alignment high while managers and frontline practitioners disagree. That gap matters because dropping AI into an already fuzzy setup magnifies confusion. AI does not rescue weak foundations. It accelerates whatever is already there: clarity or drift. So before rushing toward fancy adaptive pathways or auto-generated practice sets, the more grounded firms are ruthlessly honest about basics: data hygiene, skill frameworks, content freshness, governance, and how work outcomes tie back to capability shifts.
This blog walks through ten straight questions leaders actually ask in private. No mystique. No breathless hype. Each section offers concrete signals, trade-offs, watch-outs, and small “moves” that compound.
Table of Contents:
- What Does Being “AI Ready” for Learning and Development Really Mean?
- How Can You Honestly Assess Your Current L&D Maturity Before Bringing in AI?
- Why are Data, Content, and Context the Real Fuel Behind AI-Led L&D (Not Fancy Models)?
- How Should Leaders Prioritize Use Cases: Where Does AI Add Immediate Workforce Value?
- What Infrastructure and Stack Choices Matter Most for Scalable AI in L&D?
- How Do You Safeguard Learner Trust: Privacy, Ethics, and Bias in AI-Guided Growth?
- How Can AI Help Close Skill Gaps Faster and Where Does Human Judgment Still Rule?
- What Metrics Prove AI-Enabled L&D Impact Without Resorting to Vanity Numbers?
- How Do You Drive Adoption and Cultural Shift So People Actually Use AI Learning Tools?
- What Practical 12 to 24 Months Roadmap Moves You From Emerging to Pioneering AI-Driven L&D?
- Closing Thought
What Does Being “AI Ready” for Learning and Development Really Mean?
People toss around the phrase “AI-ready” as if it were a badge. In reality, it is less a badge and more a bundle of practical conditions. You are “ready” when adding intelligent automation, prediction, or personalization layers produces clearer workforce capability gains at a lower marginal cost than current methods, without eroding trust. That is the bar.
Break it down into eight observable pillars:
- Direction: An agreed set of priority capability shifts tied to revenue, risk, margin, growth, or compliance outcomes.
- Data spine: Clean, mapped, de-duplicated employee profile, role, performance, content, and skill signal feeds.
- Content shape: Modular, tagged, current, rights-cleared assets that a model can index or remix without stepping on licensing landmines.
- Common vocabulary: A pragmatic, living skill, and role taxonomy that stays coherent and maintained rather than perfect.
- Governance: Clear rules for data use, retention, model evaluation, escalation, and bias review.
- Stack extensibility: APIs, event capture, and identity management that allow orchestration rather than fragile one-off scripts.
- Change muscle: A track record of rolling out workflow-altering tools with adoption above baseline.
- Proof discipline: A habit of isolating variables and calculating contribution to business indicators, not stopping at participation counts.
If three or more of those are weak, the fancy personalization engine will likely stall. AI feeds on structure plus signal density. Without them, it produces plausible fluff. Mature firms treat readiness like staging a building site: clearing debris, laying drainage, marking boundaries. It is unglamorous, yet it prevents rework.
How Can You Honestly Assess Your Current L&D Maturity Before Bringing in AI?
Honest assessment begins with evidence, not aspiration. Create an inventory of significant learning or talent development initiatives delivered in the past twelve months and force a single sentence linking each to an explicit performance or risk metric, along with the hypothesized causal path. Where statements become vague or devolve into compliance phrasing, you have illuminated activity detached from outcome.
Track the median elapsed time between the formal surfacing of a capability gap and deployment of the first tailored intervention addressing it. Long delays signal process friction that AI cannot magically absorb. Examine the proportion of initiatives that advanced evaluation beyond completion and satisfaction into demonstrable skill uplift or observed behavior change. If that percentage is low, instrumentation and analytic capability must be strengthened before layering advanced inference.
Run a concise pulse with three or four high signal prompts:
- Is relevant growth support accessible in your workflow without significant context switching?
- Did a recent learning interaction change the way you executed a specific task?
- What single barrier most limits applying new knowledge?
Review responses qualitatively for repeating friction themes such as time permission, manager follow-up, content discoverability, or stale scenarios. Convert those themes into a public backlog so transparency builds credibility. Conduct a sample quality review of the top fifty most accessed content assets, flagging currency, duplication, clarity of learning objective, and presence of actionable practice. That snapshot often reveals a long tail of underperforming material siphoning attention.
Why are Data, Content, and Context the Real Fuel Behind AI-Led L&D (Not Fancy Models)?
Sophisticated models are increasingly commoditized. Behavioral and performance signals need to be unique, clean, and actionable; your content must be comprehensible, and interventions need to be delivered contextually rather than in detached portals. If role definitions are outdated and skill declarations rely on self-report without triangulation from project artifacts, code repositories, case handling transcripts, sales interactions, or product quality telemetry, then inferred gaps will be superficial. If your content stays trapped in hour-long modules with barely any useful tags, your recommendation system becomes pretty useless. It ends up suggesting broad topics like “leadership skills” instead of delivering the precise, bite-sized learning someone actually needs right now.
Context integration lifts adoption and learning density. A service agent receiving a two-minute targeted intervention appended to an active ticket about a complex escalation has higher uptake than being directed later to a general negotiation library. Negative interaction signals matter: rapid abandonment, repeated manual search after accepting a recommendation, or low voluntary re-engagement are potent indicators of mismatch.
Routine pruning of underused, outdated, or conflicting assets preserves signal integrity. Overgrown tag schemas quietly inflate manual effort and produce inconsistent usage across contributors, eroding algorithmic precision. Establish a taxonomy governance rhythm involving practitioners and data specialists to keep descriptive layers lean and relevant. All of this fuels adaptive systems; without it, incremental model improvements yield negligible practical gains. Data richness, content fitness, and context anchoring create compounding value that competitors struggle to copy quickly. These capabilities require organizational behaviors rather than simple purchases.
How Should Leaders Prioritize Use Cases: Where Does AI Add Immediate Workforce Value?
Scattershot experimentation dilutes credibility. Every company wants to chase the coolest AI demo, but that’s usually where good judgment goes to die. Prioritization benefits from a simple scoring grid weighted around business pain intensity, tractability with current data, time-to-value, trust sensitivity, and reuse potential. Plot your candidate use cases on this grid and resist the urge to start with whatever got the most applause at the last tech conference. Start with a repeatable value instead.
Common early high-yield patterns:
- Search relevance uplift: Applying semantic retrieval across legacy repositories to reduce “where is the thing?” waste minutes.
- Adaptive practice drills: Tailoring question difficulty on the fly for regulated skill domains (safety, privacy) to reduce seat time while holding mastery thresholds.
- Summarization companions: Compressing long-form internal knowledge assets into digestible briefs with source citations, saving knowledge discovery time.
- Skill signal enrichment: Inferring likely proficiency shifts from work artifacts (code quality metrics, support ticket resolution notes) to reduce reliance on self-assessment.
- Content gap heat map: Scanning role-to-skill frameworks against current asset coverage to spotlight missing micro-learning objects before major shift initiatives.
The fun stuff comes later, after trust and data spine mature. That’s when you can tackle cross-role upskilling path synthesis with multi-hop recommendations factoring adjacent skills, or real-time workflow coaching with contextual prompts inside tools, or even predictive attrition linked to skill stagnation signals. But jumping into these approaches early feels like teaching calculus before arithmetic. Ambitious? Sure. Doomed? Absolutely.
Avoid early: fully automated “career navigator” bots (risk of shallow platitudes), high-stakes performance feedback generation (tone risk), and opaque black-box proficiency scoring with no interpretability.
What Infrastructure and Stack Choices Matter Most for Scalable AI in L&D?
You do not need an extravagant architecture to start. You do need a modular, observable, secure backbone that avoids brittle coupling. Here’s the thing most vendors won’t tell you: the fancy architecture diagrams they show at conferences? Pure fantasy for 90% of organizations. What you actually need is more like building with LEGO blocks than constructing the Taj Mahal.
The foundational decisions matter more than the fun stuff. Identity and access control isn’t glamorous, but get it wrong and watch learner trust evaporate faster than water in the Sahara. You need robust single sign-on plus attribute-based access control that actually makes sense.
The technical pieces get interesting when you hit the semantic layer. Vector databases for embeddings go beyond trendy to become essential for search that actually understands intent.. But here’s the kicker: you need hybrid retrieval combining sparse and dense methods. Pure semantic search sounds great until someone searches for “SAP module MM” and gets results about chocolate because the AI thinks MM means M&Ms. Metadata filters by role, region, and compliance flags save you from these embarrassing moments. Your content pipeline needs to treat content as data, not static media lumps. Automated ingestion jobs with real linting turn chaos into order by checking tag completeness and catching duplicates.
The model layer is where over-engineering kills projects. You don’t need to build your own large language model. You need an orchestration service that can swap underlying providers without rewriting your entire business logic. OpenAI burns you with a price hike? Switch to Anthropic. Google releases something better? Swap it in. But wrap everything with guardrails—prompt templates that prevent chaos, input validation that catches nonsense, and output toxicity scans when you’re generating content because nothing torpedoes an AI initiative faster than your learning assistant suddenly spouting conspiracy theories.
How Do You Safeguard Learner Trust: Privacy, Ethics, and Bias in AI-Guided Growth?
Trust is earned by design, not by reassurance emails. Learners worry: “Who sees my assessed gaps? Will this label freeze my progress? Will the system misinterpret my background?” Address those fears concretely.
Here’s the blueprint:
- Data minimization: Collect only signals with a clear link to defined use cases. Document the linkage publicly on an internal page: “We capture search queries to improve relevance. We do not store them with performance ratings.”
- Layered consent: Provide opt-in toggles with plain language for sensitive categories (e.g., manager comments ingestion, peer feedback text).
- Bias review loop: Define protected attributes, run periodic disparate impact analysis on recommendation exposure and assessment outcomes. Include a mitigation playbook (e.g., reweighting, content diversification injection).
- Explainability: Expose “Why recommended” snippets referencing explicit attributes (“Suggested because you completed X, role requires Y, current inferred level Z”). Opaque suggestions breed skepticism.
- Human override: Managers can annotate or correct inferred skill levels; overrides feed back into model tuning.
Bias nuance: Skill inference models may under-represent exposure for employees in roles with fewer observable artifacts (e.g., negotiation skill vs code commit density). Flag “low confidence” rather than presenting a definitive score. Encourage self-evidence submission (portfolio items) to improve the signal.
How Can AI Help Close Skill Gaps Faster and Where Does Human Judgment Still Rule?
AI accelerates diagnosis, personalization, and practice adaptation in ways that would have seemed like science fiction just a few years ago. It detects patterns across thousands of micro-interactions quicker than any human facilitator could dream of, spotting trends and connections that would take teams of analysts months to uncover. Think of it as having a tireless assistant who watches every learner interaction, remembers every clicked link, and notices when someone’s struggling before they even realize it themselves.
Where AI truly shines is in the unglamorous but essential grunt work. Rapid baseline creation that used to involve weeks of surveys and assessments? AI ingests project artifacts and generates provisional skill profiles within hours. The system notices when you make the same mistake more than once during practice. Right away, it gives you a quick tip or a short two-minute video to fix it before the mistake turns into a habit. And perhaps most valuably, it serves as an early warning system, flagging cohorts where practice activity stalls before attrition spikes or performance dips.
But here’s where the human judgment matters more than ever. AI stumbles hard in the messy, nuanced world of behavioral judgment and interpersonal dynamics. Imagine asking AI to settle an office argument or tell someone they need to work on their leadership style. That’s like telling a calculator to write a love poem!
The motivational piece remains stubbornly human, too. When a skeptical employee needs to understand why a capability matters to their specific situation, AI tends to serve up generic platitudes while a good coach provides personal context and meaning. Complex narrative feedback that balances candor with encouragement, synthesizes subtle strengths with growth edges, and paints a compelling career trajectory? That’s still human territory.
What Metrics Prove AI-Enabled L&D Impact Without Resorting to Vanity Numbers?
Vanity numbers are the corporate equivalent of Instagram likes. They make you feel good but tell you nothing useful. Logins, total hours, course completions without context, raw recommendation clicks? Pure activity theater. They’re what you show the board when you want to look busy, not when you want to prove value.
The metric architecture that actually matters starts with input quality. You need to know your content coverage ratio—what percentage of critical role-skill pairs have at least two high-quality assets? Because having one dusty PDF for a critical skill isn’t learning infrastructure; it’s wishful thinking. Then track your system performance with metrics that matter to users. Search success rate tells you if people find what they need within the first three results, because nobody’s scrolling to page 47. Adaptive path compression shows you average hours saved versus those soul-crushing legacy static paths. If your AI can’t beat a PowerPoint deck, why bother?
Efficiency metrics keep you honest about resource allocation. Track your content reuse factor. How many distinct pathways does each micro-asset appear in? If you’re creating bespoke content for every scenario, you’re burning money. Monitor how many instructor hours you’ve displaced and, more importantly, what those instructors are doing now. If they’re not doing higher-value coaching, you’ve just created expensive unemployment. Don’t forget equity metrics either. Variance in skill progression across demographic segments tells you if your AI is accidentally discriminating. Keep an eye on trust and adoption every week. It’s better to track the share of learners who actually come back and use the system than to brag about how many people merely signed up.
How Do You Drive Adoption and Cultural Shift So People Actually Use AI Learning Tools?
Adoption is seldom about interface polish alone. It’s more about perceived relevance, trust, and habit formation. Cultural shift grows from repeated cycles where the system saves someone time or helps them perform better, and that story travels through the organization like good gossip.
The most effective approach starts with problem-first narratives. Don’t announce “We deployed an AI-powered semantic platform.” Instead, say “We waste 14 minutes per day hunting policy content; here’s a smarter search that cuts that in half.” People care about their pain points, not your tech stack.
Build trust through transparency. Offer clear opt-out paths (rarely used but psychologically crucial) and explicit privacy stances to reduce shadow resistance. For skeptics, provide a “slow lane” mode—basic search without the AI bells and whistles. Many graduates volunteer once they see their colleagues benefiting.
Keep iterating based on reality. Conduct friction audits by observing real sessions (with consent), noting confusion moments, and adjusting rapidly. Beware mandatory pushes with rough edges. Design for pull dynamics where colleagues show each other concrete time-savers. And please, use plain language. “Contextual Practice Suggestions” beats branded buzzwords every time. Success comes when conversations shift from “Should we use AI?” to “Can we tune the hint timing for complex cases?”
What Practical 12 to 24 Months Roadmap Moves You From Emerging to Pioneering AI-Driven L&D?
A pragmatic roadmap sequences groundwork, credibility wins, scale moves, and refinement loops. Below is a pattern that has worked for firms moving from fragmented experimentation to a recognized internal value engine. Adjust timing based on org size and baseline maturity.
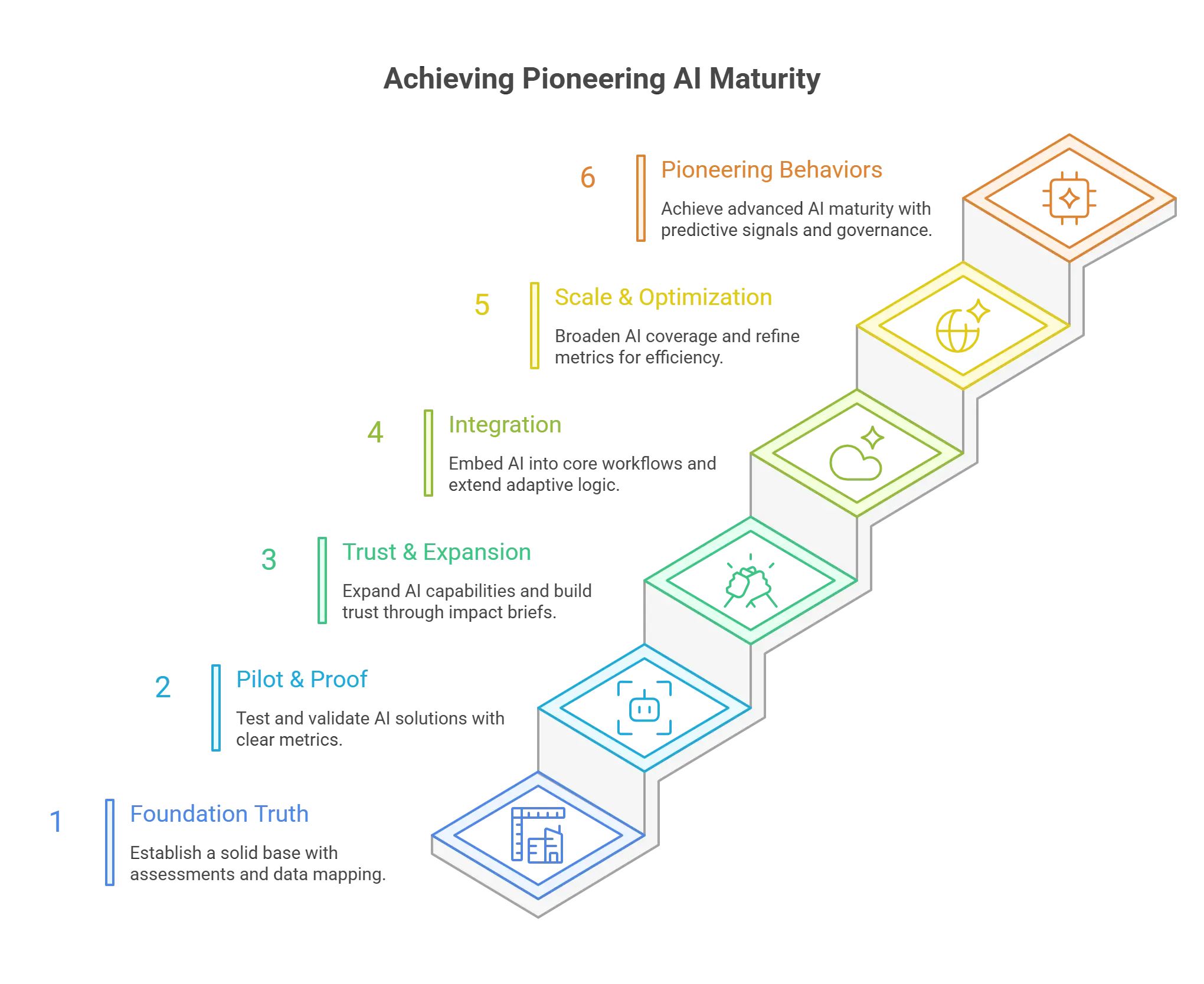
Months 0-3 (Foundation Truth)
- Run a candid maturity assessment (as outlined).
- Data spine mapping + gap remediation plan (deduplicate employee records, tag coverage baseline).
- Select 2 high-probability use cases (e.g., semantic search uplift + adaptive practice for one critical role).
Months 4–6 (Pilot & Proof)
- Deploy semantic search with a clear success metric (query success rate).
- Launch an adaptive practice pilot for targeted compliance or technical skill set.
- Establish model/prompt version control.
- Run initial bias and explainability checks even if small scale.
Months 7–9 (Trust & Expansion)
- Publish first impact brief (search time reduction, adaptive seat time compression).
- Begin skill inference enrichment using work artifacts (start narrow).
- Build living skills graph service v1 (ingest baseline taxonomy).
- Begin quarterly content freshness cycle.
Months 10–12 (Integration)
- Embed recommendations inside one core workflow tool.
- Extend adaptive logic to the second role family.
- Launch dashboard showing capability movement + business proxy link.
- Introduce a lightweight human-in-the-loop review on model explanations.
Months 13–18 (Scale & Optimization)
- Expand skill inference coverage to broader roles with confidence scoring.
- Introduce path pruning to reduce redundancy for experienced employees.
- Pilot real-time workflow micro-coaching in a limited domain.
- Conduct a second bias audit; publish mitigation actions.
- Evolve metrics from usage to contribution ratios (cost per proficiency point, ramp time delta).
Months 19–24 (Pioneering Behaviors)
- Integrate predictive early warning signals (plateau alerts) into manager dashboards.
- Launch multi-hop adjacent skill growth pathways for internal mobility.
- Refine governance: annual external review, red team simulation.
- Portfolio review: retire low-impact AI features, double down on those with the strongest ROI.
- Publish the second internal maturity map showing the shift from Emerging/Developing toward Pioneering on select pillars.
Throughout:
- Quarterly “Open Model Review” forums where product, L&D, data, and employee representatives inspect decisions.
- Continuous prompt refinement based on logged failure cases.
- Transparent backlog with community voting on improvement suggestions.
End-state signals you are nearing a pioneering tier: leaders query capability movement in the same breath as financial KPIs; employees trust the recommendation layer as a helpful companion; the system adapts as roles evolve without multi-month refactoring; and audits pass with minimal rework.
Closing Thought
AI in L&D is less a dramatic leap and more a compounding sequence of disciplined, transparent, human-centered adjustments. The Hurix Digital L&D Maturity Index made clear that few have reached the frontier. That is an opportunity, not a verdict. The firms that will stand out are those that treat readiness as craft—curating data fabric, pruning noise, sequencing use cases, protecting trust, and proving contribution without theatrics. Build that craft and “AI-driven” stops being an aspiration; it becomes the quiet, reliable engine underneath workforce growth.
Summarize with:
ChatGPTGoogle AIClaudePerplexityGrok AI

Senior Vice President
Julia brings over 20 years of global experience in digital learning and business strategy. She specializes in client success, enterprise learning solutions, and driving growth through innovation, with a focus on AI, VR, and emerging technologies across diverse industry verticals.
